这次我们来讲讲 C++/STL 里的排序算法。最后混进来的 nth_element 是选择算法,以$O(n)$的平均时间复杂度返回第 n 小的元素(若有重复元素则是排序后 n-th 位置上的元素),但采用的是快排思想,故一并介绍。
sort
我们知道 C++/STL 里的sort()是快排,但又不是教材上那种最基础的快排,是经过优化的、力图在各种最坏情况下都能取得较优表现的introSort(不过据说早期STL还是直接用快速排序的)。
在侯捷的 「STL源码剖析」 中了解到 introSort 在快排之上的改进主要有:
- 当快速排序递归层数过深时,改用堆排序,比如长度为40的数组,允许递归10层;
- 当需要排序的序列较短时,使用插入排序,STL中通常取该值为16,此处思想为插入排序对于基本有序、且较短的序列所需交换次数较少,且没有递归等额外开销;
- 选取快速排序的 pivot,采用 medain-of-three 策略,从序列头、中段、尾取三个值并以其中的中位数作为 pivot,避免快排因 pivot 选取不当出现性能退化。
思想差不多就是这样,以下扒源码验证,gcc版本为version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04),与书中一样为 SGI实现版本。
直接找到 sort 的具体实现部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename _RandomAccessIterator, typename _Compare>
inline void
__sort(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
if (__first != __last)
{
std::__introsort_loop(__first, __last,
std::__lg(__last - __first) * 2,
__comp);
std::__final_insertion_sort(__first, __last, __comp);
}
}
其中 loop 部分的代码为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
template<typename _RandomAccessIterator, typename _Size, typename _Compare>
void
__introsort_loop(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp)
{
while (__last - __first > int(_S_threshold))
{
if (__depth_limit == 0)
{
std::__partial_sort(__first, __last, __last, __comp);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
}
}
这……果然跟书里说的一模一样啊, partial_sort 是堆排序(后面还会介绍),__final_insertion_sort是对底层插入排序的一个包装,分别处理序列长度大于和小于等于16时两种情况。不过有个不一样的地方是 __lg() 函数的实现。书中的 __lg(int n) 返回的是 $2^k <= n 的最大k值$。比如 $n=40时, k=5; n=20时, k=4$,通过 for 循环对n向右移位实现。但现在该函数实现变为:
1
2
3
4
inline _GLIBCXX_CONSTEXPR int
__lg(int __n)
{ return (int)sizeof(int) * __CHAR_BIT__ - 1 - __builtin_clz(__n); }
#define __CHAR_BIT__ 8,而 __builtin_clz(int n) 是计算整数 n 前导零个数的内建函数。现在计算得到的依然是不超过 n 的 k值,但是内建函数也许是通过汇编指令集、也许是由编译器生成的汇编代码实现(//TODO:needs update),总之会得到比循环计算更好的性能。
stable_sort
书上没有介绍stable_sort,但是我们知道几种$O(nlog(n))$的排序算法只有归并排序是稳定的,能够保持序列元素原本的相对顺序。
原理就不用再介绍了,来直接看源码。__stable_sort下具体完成排序工作的是以下两个函数:
1
2
3
4
5
if (__buf.begin() == 0)
std::__inplace_stable_sort(__first, __last, __comp);
else
std::__stable_sort_adaptive(__first, __last, __buf.begin(),
_DistanceType(__buf.size()), __comp);
由于不确定__buf.begin()的含义以及这个if语句的意图,干脆这俩都看一下到底是做什么的。首先是__inplace_stable_sort:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/// This is a helper function for the stable sorting routines.
template<typename _RandomAccessIterator, typename _Compare>
void
__inplace_stable_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
if (__last - __first < 15)
{
std::__insertion_sort(__first, __last, __comp);
return;
}
_RandomAccessIterator __middle = __first + (__last - __first) / 2;
std::__inplace_stable_sort(__first, __middle, __comp);
std::__inplace_stable_sort(__middle, __last, __comp);
std::__merge_without_buffer(__first, __middle, __last,
__middle - __first,
__last - __middle,
__comp);
}
这一眼就是归并排序,并且在元素个数少于15个时也直接采用插入排序。其中值得学习的部分主要是__merge_without_buffer函数在合并两段排好序的数组时,不开辟临时空间来暂存数组元素,而是先找到通过把左边序列中较大的一半,与右边序列中较小的部分进行交换位置,从而将两段序列拆成四段更短的序列。举个例子,合并两段序列[1,3,5,7,9]和[2,4,6,8]:
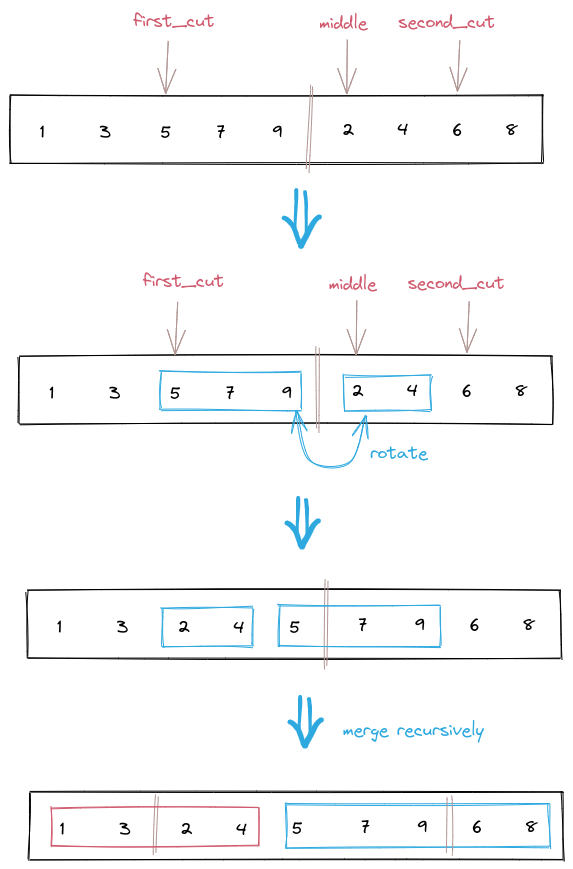
这里的 rotate 操作相当于把不断把队首的元素pop之后再追加到队尾,直到 middle 指针指向的元素往前移动到 first_cut 的位置。最后得到的前两段和后两端同样都是内部有序的待合并序列,只是序列长度都比原来更短,接下来继续进行递归直到序列中只剩两个元素,就能直接交换它们的位置然后结束合并。
接下来再看另一个__stable_sort_adaptive函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
template<typename _RandomAccessIterator, typename _Pointer,
typename _Distance, typename _Compare>
void
__stable_sort_adaptive(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Pointer __buffer, _Distance __buffer_size,
_Compare __comp)
{
const _Distance __len = (__last - __first + 1) / 2;
const _RandomAccessIterator __middle = __first + __len;
if (__len > __buffer_size)
{
std::__stable_sort_adaptive(__first, __middle, __buffer,
__buffer_size, __comp);
std::__stable_sort_adaptive(__middle, __last, __buffer,
__buffer_size, __comp);
}
else
{
std::__merge_sort_with_buffer(__first, __middle, __buffer, __comp);
std::__merge_sort_with_buffer(__middle, __last, __buffer, __comp);
}
std::__merge_adaptive(__first, __middle, __last,
_Distance(__middle - __first),
_Distance(__last - __middle),
__buffer, __buffer_size,
__comp);
}
跟着找下来发现是预先开辟好临时空间来完成合并,但不像手工实现的归并排序那样一直分割到每个区间只剩1个元素,而是先把整个序列分割为若干长度为7的区间,对每个区间使用插入排序,然后再把各个排好序的小区间两两合并起来。
总结来说,sort和stable_sort中对插入排序的使用比想像中的要多,虽然是$O(n^2)$复杂度的排序算法,但是在区间较短时反而会因为它的简单(无递归、无需额外空间,且STL对插入排序的内循环判断条件进行了优化)而比其他$O(n×log(n))$算法更有效。
partial_sort
该函数实现的是堆排序,接收三个迭代器 first, middle, last,保证 midle - first 个最小的元素在区间 [first, middle) 内,其余元素放在 [middle, last) 内,且不保证顺序。
首先对区间 [first, middle) 建最大堆,然后继续遍历 [middle, last),若碰到比堆顶大的元素,则交换两个元素位置,并将新元素下移到队中合适的位置。如此遍历完整个区间后,对 [first, middle) 的最大堆不断进行pop操作得到一个升序数组,即完成整个排序过程。
nth_element
该函数实现了 quick select 算法1,平均$O(n)$时间复杂度求数组中第 K 大(或第 K 小)的元素(经典的面试题)。实现思路类似快排,但是每次分为左右两段子区间之后,只对第 nth 元素所在子区间继续递归处理,直到第 nth 位置上的值确定为止(严格来说每次 partition 之后,pivot 所在位置的元素值就确定了,我们不断缩小分区,直到这一区间缩小到 nth 位置)。
符合本人认知的时间复杂度计算:
如果 pivot 选择得不好,最坏情况下还是会跟快排一样退化成为 $n(n^2)$(比如每次都选到极值,这样几乎每次 parition 之后区间长度都只能减小1。快排中选取 pivot 的优化策略也可用于此,这里略去不讲。
示例代码来自leetcode-215
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// cpp
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
int begin = 0, end = nums.size();
int pivotIndex = partition(nums, begin, end);
while(pivotIndex != k - 1){
if(pivotIndex < k - 1) {
begin = pivotIndex + 1;
} else {
end = pivotIndex;
}
pivotIndex = partition(nums, begin, end);
}
return nums[pivotIndex];
}
int partition(vector<int> &num, int begin, int end) {
if(end - begin == 1) {
return begin;
}
int pivot = (begin + end) / 2;
int val = num[pivot], index = begin;
swap(num[pivot], num[end - 1]);
for(int i = begin; i < end - 1; i++){
if(num[i] > val) {
swap(num[index], num[i]);
index++;
}
}
swap(num[end - 1], num[index]);
return index;
}
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// golang
func findKthLargest(nums []int, k int) int {
left, right := 0, len(nums)
pivotIndex := partition(nums, left, right)
for pivotIndex != k - 1 {
if pivotIndex < k-1 {
left = pivotIndex + 1
} else {
right = pivotIndex
}
pivotIndex = partition(nums, left, right)
}
return nums[pivotIndex]
}
func partition(nums []int, left, right int) int {
if right - left <= 0 {
return -1
}
if right - left == 1 {
return left
}
pivot := (left + right) / 2
pivotVal := nums[pivot]
nums[right - 1], nums[pivot] = nums[pivot], nums[right - 1]
index := left
for i := left; i < right - 1; i++ {
if nums[i] > pivotVal {
nums[index], nums[i] = nums[i], nums[index]
index++
}
}
nums[index], nums[right - 1] = nums[right - 1], nums[index]
return index
}
顺带,如果说明数据无法一次全部装入内存,但可以装入k数量级的数据,那么使用一个 k + 1 大小的优先队列遍历数据即可。
关于 c++/STL 的这几个函数的介绍就到这。
The End