整理两阶段锁的笔记,来填以前的坑了
2PL 理论部分
如之前所说,2PL是一种悲观的并发控制手段,通过使用2PL我们可以保证事务的可串行化。其规则说起来很简单,我们将一个事务生命周期分为两个阶段:
- 增长阶段:事务在增长阶段只能申请锁。
- 收缩阶段:一旦事务释放锁就会进入收缩阶段,在该阶段中事务只能释放锁。
非常简洁且容易记忆,以上两条规则就能保证事务串行化。但是现实又没那么简单,basic 2PL 有可能导致级联回滚(cascading aborts),如事务T1修改数据A之后进入收缩阶段,随后数据A被另一个事务T2读取,但事务T1意外终止了,因此数据A的修改被撤回,这导致T2也需要回滚,此时我们说 T1 的 abort 可能导致多个事务都需要回滚。可以加强2PL释放锁的条件避免这一情况的出现,我们可以使用 strict 2PL 协议,该协议与 basic 2PL 一样都有增长和收缩阶段,但是限制互斥锁的释放必须推迟到提交事务之后。容易发现使用 strict 2PL 其他事务就无法读到未提交数据的中间状态,能避免级联回滚,但是该协议更悲观,并发程度更低。
Q:现实中我们是否在使用 Strict 2PL(S2PL) 或 Strong Strict 2PL(SS2PL)? A:尽管教材提到 S2PL 在商用数据库系统中使用广泛,但目前许多商业数据库都使用 MVCC 而非基于锁的并发控制,因此现在现实中还在使用 2PL 的数据库应当相对而言不如 MVCC 的多。
TODO:分别列举一些使用 MVCC 和 Lock-based 的数据库。
死锁处理
对于2PL加锁的情况,根据出现死锁的必要条件:1)互斥访问,2)持有并等待,3)资源非抢占,4)循环等待;来分析是否会出现死锁。对条件1,2PL中的写操作需要申请互斥锁;对条件2,容易发现两个事务有可能占有一部分数据,并且都在等待对方占有的数据;对条件3,2PL不会抢占其他事务持有的锁和数据;对条件4,由条件2的例子就能构成一个等待的循环。因此可知2PL无法避免死锁情况的出现,我们需要额外的策略来处理死锁。
之前我们也简单提到过处理死锁问题有两类方法:死锁预防、死锁检测
死锁预防
可以通过破坏造成死锁四个必要条件之一来实现死锁预防,因此对应四种必要条件也有四种思路来进行死锁预防。
破坏互斥访问条件
这种方法恐怕有点困难,对于持有共享锁部分当然不会出现死锁情况;对于本需要互斥访问的资源,我们只能采用多个事务将修改交给某个线程统一操作的方式,但是这样做也就失去了并发的意义,还不如直接设计为写事务串行执行(如BoltDB就是写事务串行执行)。
破坏持有并等待条件
可以要求事务在执行前先申请全部需要的锁,如果有任何一个锁无法获取,就释放已获取的锁并中止运行。这样就不会有事务持有一部分锁并等待剩下的锁的情况出现,不过这虽然避免了死锁,但是也有很多缺点。如我们通常在事务执行过程中才获知它需要修改哪些数据、需要哪些锁;有些数据可能在执行一段时间后才会访问,但是我们过早给它加上了锁,降低了并发;另外这种方式容易导致事务因没有拿到全部的锁而反复重试,出现饥饿的情况…诸多缺点使得该策略也难以成为首选策略。
允许资源抢占
教材1提供了一种基于时间戳的抢占方法来进行死锁预防。首先给事务赋予一个时间戳,当某个事务请求的锁被其他事务占有时,通过时间戳判断要回滚哪个事务。
- Wait-Die:新事务回滚,这是非抢占的。
- Wound-Die:老事务回滚,这是基于抢占的。
但是允许资源抢占会造成大量的事务回滚,因而也不是常用选择。
避免循环等待
记得操作系统中曾学过银行家算法用于死锁预防,该算法实际是通过来判断资源分配之后是否仍处于安全状态来避免循环等待,从而实现死锁预防。之前因为没有实际应用过该算法,不知道它能应用在什么场景(算法有许多条件,如要求资源数已知且固定,需求数已知等),看到数据库的死锁预防时就在想为什么教材没有提到银行家算法,否则我感觉我学过的东西都串不到一起很难受。
以下是我对该问题的理解:如果我们把一个数据项的互斥锁看作仅有1份的资源(暂不考虑共享锁),则假设事务开始时需求资源数已知的情况下,是可以应用银行家算法分析的。
比如假设我们有 R1,R2,R3 三个数据项,将它们的互斥锁看作只有1份的资源,然后有 T1,T2,T3 三个事务,它们需要的资源数分别为 T1{R1:1, R2:1, R3:1}, T2{R1:0, R2:1, R3:1}, T3{R1:1, R2:1, R3:0},假设现在T1已经持有资源 R1,T2已经持有 R2,那么根据银行家算法可以画出以下表格
| alloc | max | needs | R1 R2 R3 | |
|---|---|---|---|---|
| T1 | 1 0 0 | 1 1 1 | 0 1 1 | 0 1 0 |
| T2 | 0 0 1 | 0 1 1 | 0 1 0 | |
| T3 | 0 0 0 | 1 1 0 | 1 1 0 |
可以看到此时将资源分配给 T2,满足安全状态要求,此时系统状态变为
| alloc | max | needs | R1 R2 R3 | |
|---|---|---|---|---|
| T1 | 1 0 0 | 1 1 1 | 0 1 1 | 0 1 1 |
| T2 | ||||
| T3 | 0 0 0 | 1 1 0 | 1 1 0 |
显然只能再分配给 T1,T1 执行完毕后 T3 也能得到所需资源执行,因此可以得到一个安全序列 $<T1, T2, T3>$。所以通过银行家算法管理互斥锁的授予是可行的。
但是如果我们加入了共享锁就不行了,哪怕我们把共享锁看作是无限的,但是因为一个数据项的共享锁和互斥锁不能同时授予,所以只要一个事务持有了一个共享锁或互斥锁,资源的另一种锁可授予数量就会变成0。资源数目在算法运行过程中发生了改变,银行家算法无法处理这种情况的。所以我们知道银行家算法没法处理2PL死锁问题的。
不过我们还有一种方法能破坏循环等待的条件,可以将所有锁组成一个序列,要求事务申请锁时必须按照该序列的顺序进行。这样当一个事务成功申请到第一个锁时,后面的锁肯定是开放的,如果有更早执行的事务已经持有后面的锁,它们也不会是在等待第一个锁,能够保证不会出现循环的情况。
1
2
3
4
5
6
Ti Tj Tk
[S1 S2] [S3 S4] S5 [S6] ....
Ti holds [S1, S2], waits for [S3,S4,S5,S6,...]
Tj holds [S3, S4], waits for [S5, S6,...] (gonna get S5 soon)
Tk holds [S6,...], waits for lock after S6
死锁检测
我们可以通过构造一个等待图(wait-for graph),检测图中是否存在环来判断是否存在死锁的情况。图中一个节点表示一个事务,一条有向边$E<T_i, T_j>$表示事务$T_i$在等待$T_j$的资源。则问题转为有向图中如何判断环是否存在、以及如何切割环。
我们有以下两种方法判断有向图上是否存在环:
-
DFS
DFS在邻接矩阵存储图时时间复杂度为$O(V^2)$(访问 V 个节点,每个节点尝试对 V-1 条边进行遍历),使用邻接表时为 $O(V+E)$(访问 V 个节点,每个节点对以自己为起点的边进行遍历);
-
拓扑排序
拓扑排序(找到入度为0的顶点、删除顶点及对应的边,重复该过程直到不存在入度为0的顶点为止),时间复杂度使用邻接矩阵时也是$O(V^2)$:统计 V 个节点的入度,每个节点都要看其他 V-1 个节点是否有边,删除节点和边最多为 $O(V^2)$,故总的复杂度还是$O(V^2)$;使用邻接表时同为$O(V+E)$。
通常我们使用的是DFS,因为拓扑排序虽然能够确定环是否存在,但是不一定能完全确定构成环的顶点(可能存在顶点不会被拓扑排序删掉但是它也不参与构成环),如下图节点D,此时删除D(即回滚对应事务)并没能打破死锁。
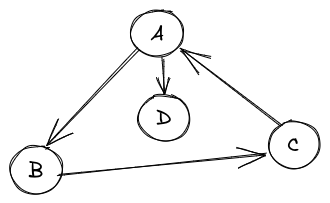
图借自 https://www.cnblogs.com/tenosdoit/p/3644225.html
实现笔记
在 Bustub project 4 的 lock manager 中,我们实现了基础的2PL协议。基本是按照教材1描述的 lock manager 来实现的:维护一个 map 存储加锁的数据项,key是该数据项的id,value是申请该数据项锁的事务队列。每次出现新的加锁请求就将其放到数据项对应的队列末尾;每次释放锁时,从队列中找出一个排在最前面的事务来为它授予锁。
如果 C++ 的 condition_variable 能够保证每次唤醒的顺序也是按照等待开始的顺序的话,那么我们在解除互斥锁时只要 notify_one 唤醒一个线程就好了;但是 C++ 的 API 文档中并没有提到唤醒顺序是否能够保障,因此我还是使用了 notify_all 唤醒所有等待线程检查是否自己在等待队列最前面。这样虽然正确性得到保障,但是似乎增加了额外开销。
另外,根据proj要求我们还实现了 Upgrading,将共享锁升级为互斥锁。刚开始做的时候我犯了个错误,认为如果当前已分配锁的队列最前面的事务可以直接升级为互斥锁(如果是它请求的upgrading);但是如果除它以外还有事务获取了共享锁,那么这里的升级就不应该成功。我发现这个问题之后先改为令其他持有共享锁的事务 abort,再一想感觉也不对,因为持有共享锁的事务可能很多,会导致大量事务回滚。所以最后改为 Upgrade 时将事务重新排到队尾,当队列中已存在的事务都获得锁并释放之后,才将允许升级为互斥锁。因为这部分并没有充足的测试用例,无法判断这种思路的是否符合正确。
update:我在想如果构造这样一个测试用例:首先生成若干读事务 T1,T2,T3 均获取数据D1的共享锁,生成若干写事务 T4,T5,T6 在等待 D1 授予互斥锁,然后T1请求 Upgrade,如果按照上面描述的逻辑,如果 T1 需要等待 T4,T5,T6 执行并释放锁之后才能升级的话,存在违背 Repeatable_Read 的可能性。目前认为正确的做法应该是保持 T1 在队列中的位置,阻塞后续申请锁的请求,等待当前已授予的共享锁释放后完成升级(所以我的代码要修改 😭)
update2 of update:上面描述的升级方法,可能造成不可重复读吗?T2、T3再次加锁后会读到D1不一样的值吗?
不会。因为根据2PL加锁和释放锁的要求,T1能够升级锁的时候,T2、T3已经进入shrinking阶段,不会再申请锁、也就不会再读取数据D1了。
不同隔离等级的实现方式
最后要记录的是 Bustub 事务共需实现3种隔离等级:Repeatable_Read, Read_Committed, Read_Uncommitted。因为课本上对于隔离等级的实现只是介绍了几种并发控制手段,没有具体介绍如何使用某种并发控制来实现不同的隔离等级,所以对于这块概念一直都很迷糊。感谢 Andy 让我终于在 coding 中明白了 2PL 实现的细节,主要区别体现在共享锁的释放时机上。以下是使用2PL时各个隔离等级的实现方式:
Serializable:strict 2PL,加上索引锁;事务开始时要给所有数据项加锁。(索引锁我们在 Phantom Problom 中简要介绍)
不太明白最后这句说明的必要性,按我的理解来说 2PL 本身就应该在使用数据之前为其加锁;难道这里说的是加锁过程要发生在任何的修改之前?
差别在于:前者可能出现先对数据块A加锁、读取和修改,处理完毕之后再对数据块B尝试加锁、读取,但是这一过程中可能有其他并行事务已经将第二块数据修改了(比如下图中的例子),这不满足可串行化的要求,因此要求在事务一开始执行时就将所有数据项加锁。 // TODO:但我们是否并非总是能在事务开始时就确定所有需要读取和修改的数据?比如包含嵌套子查询的SQL
Repeatable_Read:S2PL。
Read_Committed:在S2PL的基础上,申请到共享锁之后立即释放。
我曾有个疑问:既然拿到共享锁之后立刻释放了,那我们有申请它的必要吗?后来发现可以用下图左一的例子来解答:申请共享锁是为了确定当前没有其他事务在修改该数据项(不读取持有互斥锁的未提交数据),立刻释放是为了让其他事务能够更早拿到互斥锁(相对于RR隔离级别来说能提高并发度),完全不加共享锁的话就是读未提交了。
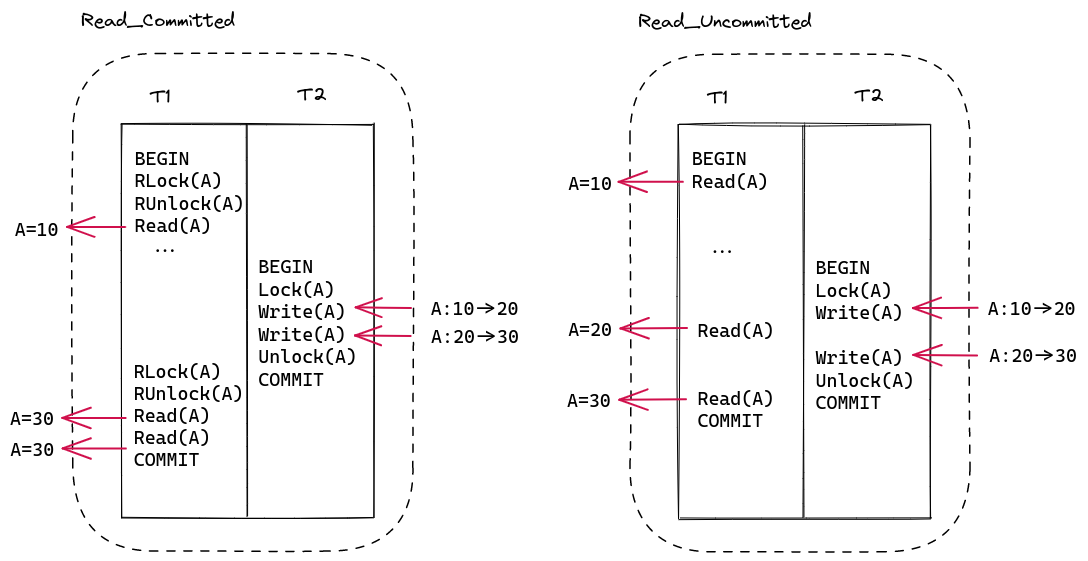
Read_Uncommitted:S2PL 的基础上去掉共享锁。如图,没有共享锁的话就有机会读到事务提交前的中间状态。
总结
// TODO
The End