引 - 缓存替换策略
首次接触缓存替换算法,是大二的操作系统课,讲内存页面替换的时候(操作系统概念第七版第9章)。因为时间太久了,所以翻教材回忆了一下当初学的替换算法都有哪些。
- 最优替换算法:替换未来最长时间不会使用的页,保证miss最少,但因为实际应用中不能预知未来所以无法实现,用于理论分析。
- FIFO:First In First Out,替换最旧的缓存页,使用队列实现,实现简单miss率高。
- LRU:Least Recently Used,替换最长时间没有使用的缓存页,较优的实现方式是采用链表记录页面使用顺序+哈希表记录页编号到链表的映射,是使用较为广泛的一种替换算法。教材中提到的在硬件上实现可以通过计数器或栈的方式。
- 近似LRU:对于硬件不支持实现LRU的情况,采用其他算法实现达到近似LRU算法,此略。
- LFU:Least Frequently Used,替换使用次数最少的页,理由是热点页面可能具有更大的引用次数,实现上可以采用双向链表记录页的使用次数+哈希表记录页编号到链表中页的位置的映射。
- MFU:Most Frequently Used,替换使用次数最多的页,理由是刚缓存的页面使用次数还比较少,与LFU实现方式基本类似,都是基于计数的算法。教材提到这两种算法并不常用,不单因为实现较复杂,且不能逼近最优替换算法。
后来数据库课程里的数据库缓冲区再次接触到缓存替换算法。教材(数据库系统概念第六版11.8章)里提到数据库缓存里最常用的依然是LRU算法。但是在数据库中,我们是可以根据SQL来推断未来将要访问哪部分数据的,比如查询 select * from table1 join table2 on table1.id == table2.id ,对于这样的表连接查询,executor会使用类似以下的双重循环来完成:
1
2
3
4
5
6
7
8
9
for r1 in table1; then do
for r2 in table2; then do
if r1.id == r2.id;
then
q := r1 join r2
put q into query result
fi
end
end
对于 table2 中刚使用的块 r2,它是最近访问次数最多的块,但要到下一轮内层循环开始才会再次使用;而最近最少使用的 table2 块有可能是下一个马上要使用的(如果内存够大没有,还没将它替换出去),这种场景下MFU的性能是更优的。
另外,数据库的缓存替换还有一个概念(在操作系统教材里没提及),pinned block,即某块内存在更新时需要被pinned在内存里不允许写回磁盘。很多操作系统不支持这种操作(TODO:需要更多了解
本文主要介绍一下LRU和LFU的实现,用leetcode的146 LRU Cache和460 LFU Cache展示具体实现。(其实是正好在leetcode做了这两道想顺便记一下)
LRU实现
LRU需要提供的基本操作就是 Put 和 Get 。Get 从缓存中返回一个页面;Put 将一个页面加入缓存中,如果当前缓存已满,选择一个最旧的页面作为 victim 驱逐出去然后再放入新页面。不过实际实现里 LRU 操作的可能只是页面编号而不是真正的页面,由LRU算法计算出要替换哪个页面,实际的读取和替换操作交由其他组件完成。
一种最简单的实现方式是使用一个双向链表表示 LRU 缓存,链表头部是最近访问的,尾部是最旧的;这样 Put 可以以O(1)时间复杂度删掉队尾元素(如果已满),然后O(1)复杂度将新元素插入开头。
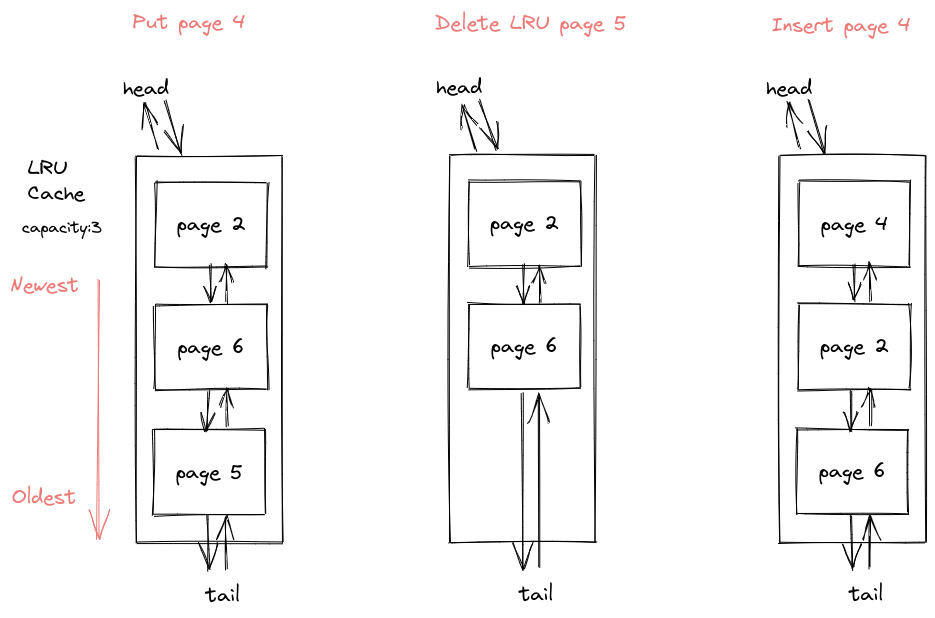
但是 Get 过程需要O(n)复杂度遍历整个链表来找到对应页面,然后再把该页移到开头。
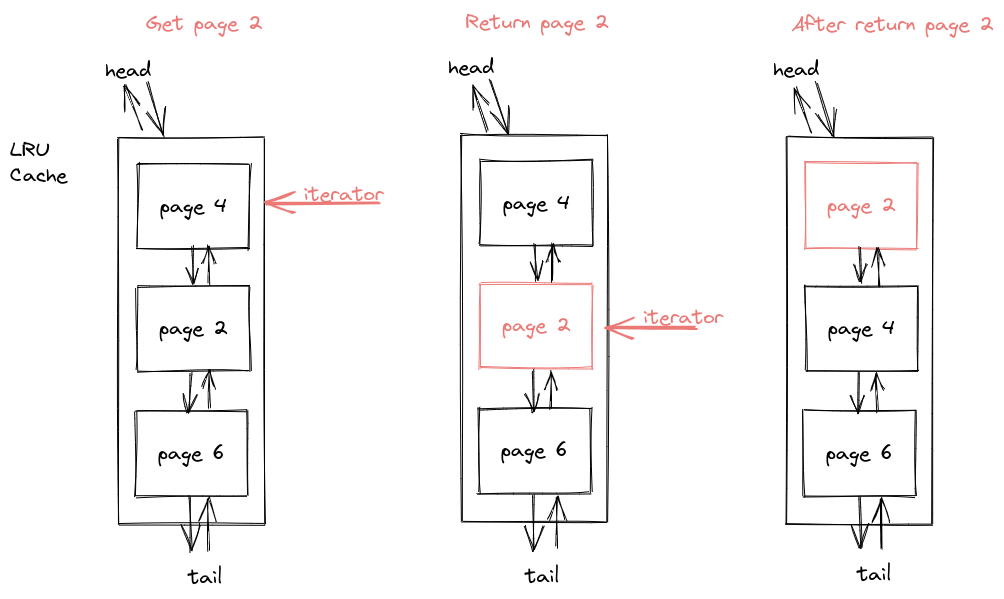
上述的实现虽然插入操作很快了,但是查询的性能肯定是不够好的。而我们使用哈希表的查询平均是O(1)时间复杂度,因此容易想到使用哈希表的方式来加快 LRU 的查找操作,所以加入一个哈希表记录页面在队列中的位置。查找操作就可以变为O(1)复杂度在哈系表中查找页面地址,然后O(1)复杂度访问和修改。这样就得到了优化后的方案二:
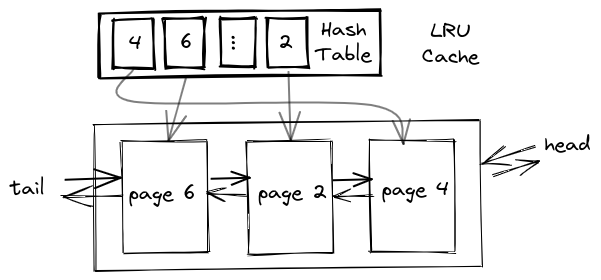
以下是我leetcode中的渣实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
class LRUCache {
typedef list<pair<int, int>> LruList;
typedef unordered_map<int, LruList::iterator> LruHashTable;
int _capacity;
LruList lru;
LruHashTable pageAddr;
void useKey(LruHashTable::iterator iter) {
lru.push_front(*(iter->second));
lru.erase(iter->second);
iter->second = lru.begin();
}
public:
LRUCache(int capacity):_capacity(capacity) {
}
int get(int key) {
auto it = pageAddr.find(key);
if (it != pageAddr.end()){
useKey(it);
return lru.front().second;
}
return -1;
}
void put(int key, int value) {
auto it = pageAddr.find(key);
if (it != pageAddr.end()) {
useKey(it);
it->second->second = value;
return ;
}
if( lru.size() >= _capacity ){
auto victim = lru.back();
lru.pop_back();
pageAddr.erase(victim.first);
}
lru.push_front({key, value});
pageAddr[key] = lru.begin();
}
};
看到知乎一个专栏和评论里面有关于方案二中使用单向链表而非双向链表是否可行的讨论,也是挺有道理的。首先我们需要链表的尾指针便于删除末尾元素,一般单向链表不带尾指针(带尾指针的单向链表好像没有意义,通过尾指针删除元素依然需要获取并修改它的前继节点next指针,这样依然需要通过遍历完成)。因此结论是用也可以,但是效率很低。
Bustub中实现的LRU
Bustub是 CMU 15-445 附带的课程项目,其中 buffer pool manager 部分要实现一个 LRU replacer。与上面leetcode题目里有些不同的是 Bustub 中 LRU 存的是能够被替换出去的页面。提供三个API:Pin, Unpin, Victim
- Victim:从 LRU 中选取将被替换出去的页面,根据上面的设计我们直接取链表末尾的页面即可;
- Pin 表示页面要被固定在内存中不允许被替换,因此直接将页面从 LRU 中删除;
- Unpin 与Pin相对,表示页面可以被替换,因此对应操作是将页面加入 LRU,如果页面本身已经在 LRU 里则移动到链表首部,表示最近刚使用过。
我虽然给 LRU 加了锁,但是 BPM 中也用了一个互斥锁,这里给 LRU 加的锁应该没有必要。其余实现跟上面 leetcode 的没有大的差别,遵守课程要求这里就不把我的实现贴上来了。
Redis中的 LRU
关于 Redis 中缓存替换策略的实现,不少博客介绍的 Redis 用的是近似 LRU 算法,后来加入 LFU,可以在配置文件中配置。
我查阅目前最新源码中的 redis.conf,发现除了这两种替换算法,它还实现有一种 volatile-ttl 替换策略,是选择离失效时间最近的 key 驱逐出去。
1
2
3
4
5
6
7
8
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
根据配置文件中的注释,Redis 出于节省内存的考虑没有采用双向链表+哈希表的实现,而是采用每个key使用一个24-bit时间戳来实现近似 LRU/LFU 算法。具体实现为从所有数据中随机选择 n 个 key 值,然后再根据时间戳挑选最近最少使用的那个作为 victim,实验表明默认配置的 n = 5 能达到不错的近似效果。另外还看到有这样的说法是双向链表+哈希的方案,并发情况下链表的head节点需要有访问控制,因此效率可能也会比时间戳近似 LRU 有所下降。
1
2
3
4
5
6
7
8
# LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
# algorithms (in order to save memory), so you can tune it for speed or
# accuracy. By default Redis will check five keys and pick the one that was
# used least recently, you can change the sample size using the following
# configuration directive.
#
# The default of 5 produces good enough results. 10 Approximates very closely
# true LRU but costs more CPU. 3 is faster but not very accurate.
以下是 LRU 算法调用链的主要代码分析。
源码中 server.c 中的 processCommand 函数有以下代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/* Handle the maxmemory directive.
*
* Note that we do not want to reclaim memory if we are here re-entering
* the event loop since there is a busy Lua script running in timeout
* condition, to avoid mixing the propagation of scripts with the
* propagation of DELs due to eviction. */
if (server.maxmemory && !scriptIsTimedout()) {
int out_of_memory = (performEvictions() == EVICT_FAIL);
/* performEvictions may evict keys, so we need flush pending tracking
* invalidation keys. If we don't do this, we may get an invalidation
* message after we perform operation on the key, where in fact this
* message belongs to the old value of the key before it gets evicted.*/
trackingHandlePendingKeyInvalidations();
...
}
其中的 performEvictions 函数负责在内存超过阈值时,释放数据获取空闲内存,具体实现在 evict.c 中。Redis 中 LRU 部分的主要代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
{
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL) {
unsigned long total_keys = 0, keys;
/* We don't want to make local-db choices when expiring keys,
* so to start populate the eviction pool sampling keys from
* every DB. */
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
if (!total_keys) break; /* No keys to evict. */
/* Go backward from best to worst element to evict. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[bestdbid].dict,
pool[k].key);
} else {
de = dictFind(server.db[bestdbid].expires,
pool[k].key);
}
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... Iterate again. */
}
}
}
}
代码片段17行的 evictionPoolPopulate 函数会从所有数据中随机挑选一些 entries,返回一个按照时间戳排好序的数组;
24~49行的 for 循环从空闲时间最长的 key (也就是数组最后一个)开始进行有效性检查,如果 key 存在且能被删除,就把它删掉;否则就继续遍历下一个直到能够删除一个元素为止。删除元素的过程一直进行到能够释放出 mem_tofree 所要求的空间大小为止,如果不能达到则返回 EVICT_FAIL 错误码,这会导致 processCommand 拒绝执行命令,返回 oom 异常。
生成sample的逻辑:生成随机数,如果对应bucket不为空就取出来作为样本,空的话就顺序往后查一小段,这一段全都是空的就重新重新查看一个新的随机位置,直到产生 n 个样本。
// TODO: dictFind进行了什么检查?什么情况下删不掉?key失效?正在修改?
其实说起来 Redis 中 LRU 设计并不复杂,没有使用双向链表和哈希表,而是用时间戳来实现近似 LRU,节省了内存还能达到与标准 LRU 算法相近的效果,这样的设计思想接下来似乎很有用。
LFU实现
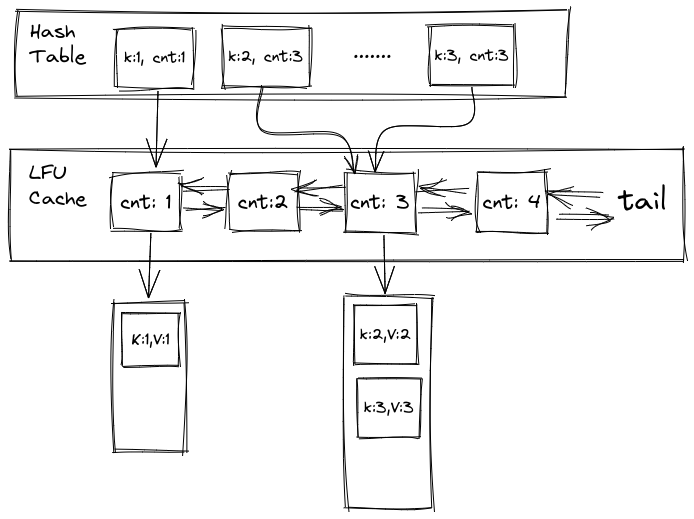
LFU 需要统计页面的访问次数,我们需要把所有访问频率相同的页面归到一起,就不能像 LRU 那样只用一个双向链表存储了。比较自然的想到用一个 map 来实现 frequency 到 pages 的映射,然后还需要使用一个哈希表记录 key 到 frequency 的映射,加快我们的查找操作,因此有了下面第一个版本的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
// 没有达到O(1)查询的实现(accpeted)
class LFUCache {
typedef int KEY;
typedef int VALUE;
typedef int COUNT;
unordered_map<KEY, pair<VALUE, COUNT>> table;
map<COUNT, list<KEY>> useCount;
int _capacity;
public:
LFUCache(int capacity):_capacity(capacity) {
}
int get(int key) {
auto it = table.find(key);
if (it != table.end()) {
increase(key);
return it->second.first;
}
return -1;
}
void put(int key, int value) {
if(_capacity == 0) {
return;
}
auto it = table.find(key);
if (it != table.end()){
increase(key);
it->second.first = value;
return ;
}
if (table.size() >= _capacity){
auto &lfuList = useCount.begin()->second;
int victim = lfuList.front();
lfuList.pop_front();
table.erase(victim);
if (lfuList.size() == 0){
useCount.erase(useCount.begin());
}
}
table[key] = pair<VALUE, COUNT>{value, 1};
useCount[1].push_back(key);
}
void increase(int key){
int cnt = table[key].second;
table[key].second++;
useCount[cnt+1].push_back(key);
auto &lfuList = useCount[cnt];
auto it = find(lfuList.begin(), lfuList.end(), key);
lfuList.erase(it);
if(lfuList.size() == 0){
useCount.erase(cnt);
}
}
};
这一版本实现的缺点是查找时,先根据 key 获取该页面的访问频率,然后找到该频率的 bucket 进行顺序查找(如下图),这步操作导致查询不能达到O(1)复杂度;另外图省事使用的STL也导致了空间浪费,frequency存储了两次,key也存了两次,还存在优化空间。
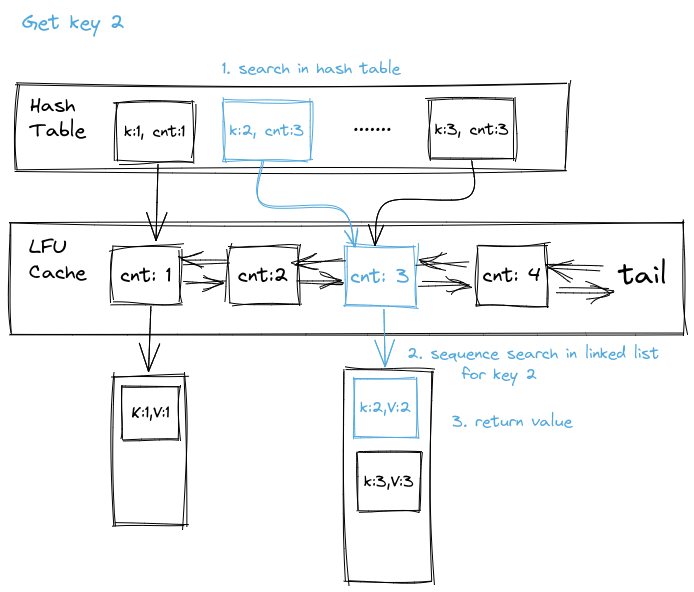
随后搜资料的时候看到一种插入和查询都是O(1)复杂度的实现方法。比起上个版本,这个版本中第一个 map 不再是 key 到 frequency 的映射了,而是 key 到 bucket 中页面的具体存储位置的映射,也就是可以直接通过 key 找到页面。访问页面之后可以通过 parent 指针(图中为了简便每个 bucket 只画了一个 parent 指针,实际每个 page 都有)直接将页面放入下一个 bucket 中,避免了之前顺序查找页面的开销。
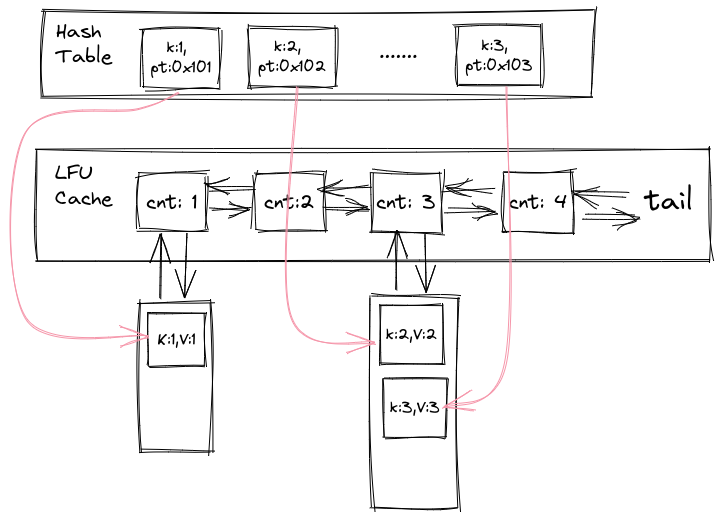
// TODO: 使用 STL 实现O(1)插入/删除的代码
Redis中的LFU
Redis 中 LFU 实现在上面介绍 LRU 的代码片段中也有涉及,区别在于evictionPoolPopulate随机选择样本时,LRU 是按照空闲时间从大到小排序,而 LFU 是按照 key 的使用频率的倒数排序,因此用得少的样本同样排在后面,会优先尝试替换出去。
另外一点是这里计算访问频率并不是真的每访问一次,counter 就会加一。Redis 这部分实现的逻辑是,counter 上限为255,当 counter 越大、越接近255,每次访问时 counter 加一的概率越小。具体实现参见 ecivt.c 中的代码片段。
1
2
3
4
5
6
7
8
9
10
11
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
// TODO:这样实现的好处?避免溢出和提供一些随机性(并非严格将访问次数最多的替换出去)?
总结
这次比较细致地学习了 LFU 和 LRU 两种缓存替换算法及其最优实现,同时通过源码对 Redis 中的相关实现进行了学习。Redis 中没有采用双向链表和哈希表的方式来实现缓存替换算法,近似LRU是通过一个24-bit时间戳实现的;LFU则依然是维护一个计数器来选择需要被替换的k/v。
The End