这一节读了两次没完全搞懂 Joint Consensus 怎么使用 $ C_{old,new} $,然后搜了一些博客发现居然又提到每次增删只变更1个节点的单步成员变更,踏马搞得我更迷糊了;奈何被问到了,不得不看。后来发现单步成员变更原来是作者博士论文1里提的,在 extended version 那篇里只涉及Joint Consensus(一种两阶段式的成员变更方法,只是因为 changes 有两个阶段才称之为两阶段,跟2PC之类的并无关系)。行吧,一点一点来搞清楚。
Single Server Approach
先明确一点:两种成员变更方法都是在线更新的,无需关闭整个集群重新配置集群信息;如果能接受 offline 更新那就不用这些复杂步骤了
虽然作者在博士论文里写道,因为单步变更实现更简单,且能通过多次单步变更来完成任意大小集群的配置,更推荐采用单步变更的方式。但是后来作者发现论文中描述的单步成员变更其实存在bug2,3,需要加入一些额外机制。对我而言,我是先看了单步变更的原理才逐渐明白后面 Joint Censensus 是要解决什么问题。
首先来看如何进行单步成员变更(single-server membership changes)。
- 每次只能增/删1个节点,这也是为什么被称为单步节点变更;
- 进行节点成员增/删时,leader 首先将 conf 的变更(也就是集群成员的信息)写入日志,新配置记为 $C_{new}$,与此相对的旧配置记为$C_{old}$;收到该日志消息的节点可以立即应用新配置信息,不用等待日志提交;应用了配置信息意味着节点会看到集群成员信息的改变,如原有4个节点现变为3个节点,选举/共识时发送/等待信息的数量也需要改变(原本选举需要3票当选,现在需要2票;另外成员的地址也可能改变)
- leader 只有在一次变更完成之后(conf 变更日志提交)才能开始下一次成员变更
该过程的步骤基本就上述几点,还是非常简单的。这一过程不会干扰集群正常处理请求的逻辑,在发生成员变更过程中集群服务依然可用,论文 section 4.2 花了不少篇幅来阐述。我们这里主要关注为什么单步成员变更能够保证 raft 的正确性。
思考:成员变更过程会出现什么问题?
因为每个节点收到集群变更消息的时间无法统一,会出现一部分节点已经接受了新配置 $C_{new}$,而另一部分节点还没收到消息、依然根据$C_{old}$配置来安排行为逻辑的情况。这一过程会出现什么问题呢,extend version 论文4中提到如果原3个节点的集群 $[1,2,3]$ 加入2个节点 $[4,5]$,现在某个时刻只有节点3 收到了新配置消息,此时$[3,4,5]$ 已经可以构成多数派选举出一个 leader 了(通常是3当选,因为4和5的日志还是空的);但是对于节点 $[1,2]$ 来说,它们也认为自己还是 3 节点集群中的多数派(因为它们没收到消息并不知道集群要变为5个节点),它俩也能选出一个 leader。这就可能导致一个任期内同时出现 2 个 leader,破坏了 raft 一个任期最多一名 leader 的性质。
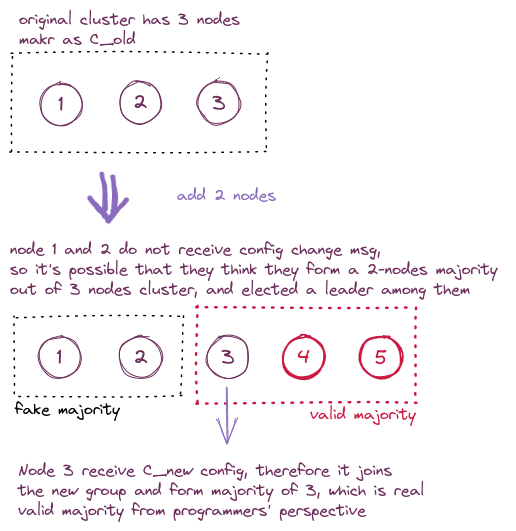
那么单步成员变更如何解决这一问题呢,论文中把这一问题归结为一次变更多个成员时,可能出现两个不相交的多数派导致的,那么一个自然的解决思路是:只要保证两个多数派之间节点有重合不就好了(论文里这一说法花了我可多功夫来理解)。而只要每次增/删只改动一个节点,就可以满足这一条件。
这样说下来肯定看得是一头雾水,我们还是来看图吧。因为每次变更只涉及1个节点,那么根据多数派至少需要 $\lfloor \frac{n}{2} \rfloor + 1$ 个节点的要求,至少会有1个节点同时存在于 $C_{old}$ 和 $C_{old,new}$ 的多数派中,两个多数派再少一票都无法构成多数派了,所以这个节点的投票是决定 leader 在哪一派中出现的关键,它投给哪一派,leader 就会产生在哪边。因为节点一个任期只能投一票,所以也不会出现两个 leader 的情况。
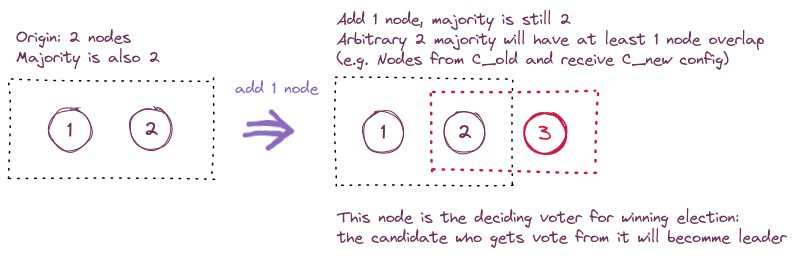
任意奇数偶数个节点的情况都与此类似,如果出现更多关键节点(中间重合部分的节点),就更不会出现双主的情况了。偷个懒就不画图了,原作者论文里有更多介绍。
$C_{old}$ 和 $C_{new}$ 节点的行为会有何不同?
$C_{old}$ 不知道 $C_{new}$,请求投票和统计票数都不管 $C_{old}$;但 $C_{new}$ 节点是知道 $C_{old}$节点的,也会向$C_{old}$发送 voteRequest 消息并统计他们的票数。至于 $C_{old}$ 收到消息后是否会投票给 $C_{new}$ 节点,就目前我对整个框架的理解应该是可能会投的。
那么上述变更出现的bug是什么呢,简单概括是 leader 在成员变更中发生切换的话,可能造成已提交日志的丢失。解决方法是在原有基础上,限制 leader 需要提交至少一条属于自己任期的日志(一般来说是每个leader当选之后写入的noop日志),才能提交成员变更的日志。
// TODO:more description and solution for this bug
Second Approach: Joint Consensus
Joint Consensus 过程稍微复杂一些,可以分为两个阶段:
- leader 将 $C_{old,new}$ 配置的变更写到日志中,然后广播给整个集群;收到新配置的节点可以立即应用该配置;在该配置下日志的提交需要 $C_{old}$ 和 $C_{old,new}$ 中的多数派都同意才能完成;举个例子,如old为{1,2,3},new为{1,2,3,4,5},那么此时提交一条日志至少需要{1,2,3}中任意两个(如{1,2}或{2,3},即old的多数派)加上 {1,2,3,4,5}中任意三个(比如{3,4,5}或{2,3,5}),这样两组节点的共识;这能保证不会出现双主的情况;
值得注意的是在上面的例子里,因为new的集群里依然包括old节点,所以old{1,2,3}也能参与new多数派的构成,比如{2,3,5}或{1,2,3}这样一组节点既是old的多数派也是new的多数派,此时整个集群最少只要3个节点存活就能满足Joint Consensus来提交日志;
另一种情况是old{1,2,3},new{3,4,5,6,7},先删除2个节点再添加4个,那么此时就需要old中的2个节点和new中的3个节点,共4~5个节点存活才能提交日志并进入下一阶段;
还有一点,节点收到$C_{old, new}$日志不代表该节点最终就是new集群的成员,如上一段例子中的old{1,2,3},new{3,4,5,6,7},其中的{1,2}不在new集群中,但是它俩同样收到$C_{old, new}$作为过渡节点参与Joint Consensus的日志提交,在2阶段完成之后,{1,2}会下线(或者被Leader当作已经下线)。
-
当配置变更的日志被提交之后,因为此时只有 $C_{old,new}$ 的节点才有可能被选为新 leader(包含一条新的配置变更日志),此时 leader 开始将 $C_{new}$ 配置日志广播给集群中的new节点(此时日志的提交还是需要1阶段中的两个多数派);当$C_new$日志提交后,集群就可以更新配置来只通过new节点的多数派提交日志了,此时任何old和{old,new}的过渡节点都不可能再成为Leader,这些节点在收到$C_new$日志后更新自己配置,如果发现自己不在new集群则可以自行下线;
Q:对论文中图里的情况,此时{old, new}只复制到3(leader),4,5上,根据Joint Consensus,此时{old, new}并不算提交;如果3是leader,发生了故障,新leader有可能由1,2构成的old多数派产生,此时也许会把变更抹掉,这种情况如何处理?
possible A: 此时的情况就是成员变更日志未提交,如果后续无法完成提交的话,客户端应该会因为该请求超时而重试;
// TODO: TiKV和etcd关于Joint Consensus的实现,与论文描述略有不同,同时也引入了新bug(某种特殊情况下出现多数派存在却无法提交日志的情况)和修复该bug的解决方式; // https://github.com/etcd-io/etcd/issues/12359
小结
根据我了解的实现历史,etcd最开始采用的是比较简单的单步成员变更实现,在raft作者发现单步变更的bug后,虽然提出了相应的修复方法,但是出于变更速度的考虑等因素/* TODO:待考证 /最后还是采用了Joint Consensus的方式;pingcap作为etcd社区的参与者也在这一实现中做了贡献/指发现bug并提出解决方法*/。
近期没法做一个简单的成员变更实现来进一步学习啦,之后的计划大概会是补全单步变更和Joint Consensus在etcd实现中遇到的bug,只做了解不再进一步搞代码了吧;