0 序
这一系列都是读论文,尝试理解和解读经典论文的思想、这样设计的优势,因此博客内容基本可以看作是对论文的翻译或者重新编排,可能加入一些自己的理解,但是不一定能保证正确性。
本文主要想回答两个问题: True Time 是什么、如何通过 True Time 保证 Spanner 的一致性(如何用于并发控制);因此可能得顺带了解一下 Spanner。
1 什么是 Spanner
F1 和 Spanner 差不多同时期在谷歌发展起来的,各自的论文中也有对方的简要介绍;不过还是 F1 论文里概括 Spanner 的特点比较精炼(甚至比 spanner 的 abstract 和 intro 更易懂),我们先通过这个来看看 Spanner 的大致思想吧。
简单概括来说,Spanner 是一个分布式数据库,通过 Paxos 共识实现多个数据中心的数据同步/一致,具有很高的可用性和可扩展性。不过 Paxos 参与共识的节点越多,提交的延迟通常就会越高,所以一般使用 Spanner 的应用可能会采用 3~5 个 Paxos Replica;可以通过添加不参与 Paxos 投票的 Ready-Only Replica 来提高读事务的吞吐量。
Spanner 能够保证读写事务的可串行化(linearizability),这是通过 Spanner 中使用的 TrueTime 时间戳来对分布式事务进行排序来实现的:每个事务需要获取时间戳,如果事务 $T_1$ 的提交时间戳早于 $T_2$ 的开始时间戳,那么 $T_1$ 的提交时间戳也保证早于 $ T_2$ 的提交时间戳。简而言之就是可以通过按照时间戳的顺序来对事务进行排序,Spanner 能保证事务的并发执行结果与按照时间戳先后的顺序串行执行得到的结果一致。TrueTime 其实与一个单点的全局时间戳(比方说TSO)功能相差不大,但区别在于 TrueTime 是全球规模的授时,哪怕是相隔整个太平洋,获取 TrueTime 时间戳的延迟也并不大;这是 TSO 无法比拟的:假如我的 TSO 部署在中国,那么位于美国的数据节点申请时间戳时,延迟会肯定远远高于在中国的节点。谷歌如何实现 TrueTime 我们稍后阅读论文时会具体介绍(但是不一定学得来)。
Spanner 存储数据的方式是将数据按照 $(key:string, timestamp:int64) \rightarrow string$ 的形式组织成B树存放在 Colosus 文件系统中的。这样的存储格式令 Spanner 可以提供数据的多个版本,这也是后面 Spanner 能够实现 lock-free read-only txns // TODO:与多版本数据有关系吗 // 和 Snapshot Read 的基础。
另外,Spanner 还支持 SQL 查询,但是论文中没太多介绍;F1 中倒是支持了更丰富的 SQL 语法,包括 F1 定义的一些新的语法如 Proto Join 等。
// TODO: Colosus 以及 GFS
顺带一提,TiDB 号称是 Spanner 的开源实现,基本思想和主要框架应与 Spanner 如出一辙;感兴趣的读者也许可以通过 TiKV 的社区、相关博客或者源码了解它的实现,虽然 TiDB 结合自身的应用场景在不少地方做了改进,但还是能从中看出 Spanner 的影子,个人认为了解 TiDB 和 Spanner 能同时促进对这两个数据库的理解。
就我目前理解而言,能够举出的 TiKV 实现与 Spanner 不同之处有:1.TiDB 的时间戳采用的是 TSO(Timestamp Oracle,可简单理解为一个单点的时钟服务) 中心授时的方式1(开源的毕竟还是难以跟谷歌的商业解决方案相比),加上 etcd 用三个节点提供容错,甚至组件名称还用的是跟 Spanner 中一样的 Placement Driver;2.TiDB 的共识算法采用 Raft, Spanner 用的是 Paxos;3.Spanner 中的分布式事务采用的是 2PC 协议,而 TiDB 采用的是 Percolator 事务模型2。Percolator 我们上次简单写了一篇介绍,感兴趣可以看看。
2 Spanner架构
就直接借论文里的图来介绍了。
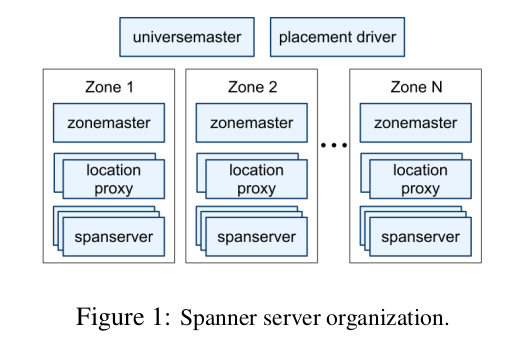
一个 Spanner 集群(称为 universe)由若干个 zone 组成,我们可以简单认为一个 zone 对应一个数据中心;所以每个 zone 内部会有成百上千台 spanserver 存储数据。图中的 zonemaster 负责将数据分发到它管辖的 spanserver 中; location proxy 帮助客户端定位数据存储位置;universemaster 是查看整个集群信息的命令行工具;placement driver 是负责在 spanserver 之间移动数据,帮助负载均衡或者恢复备份的。zonemaster、location proxy、universemaster 和 placement driver 我们后面都不会再介绍(因为论文里没有深入讲,可能技术上也没有太多 novelty,虽然我蛮想知道的;不过这些细节写进论文确实太浪费篇幅了)。
不过 zone 只是概念上(或者说配置上)用来分隔 spanserver 的;实际也可以根据应用场景的需求,在同一个数据中心里设置多个 zone。
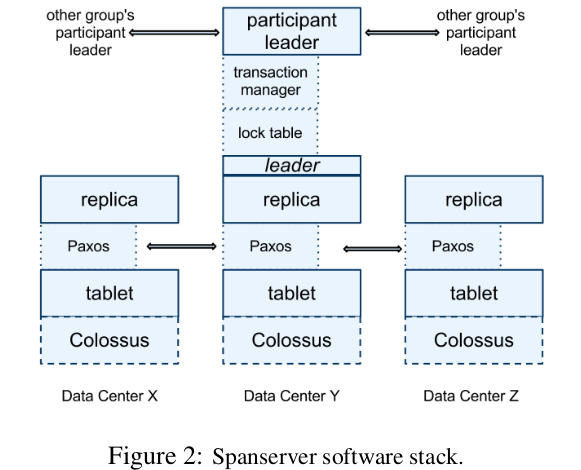
我们还是来看 Paxos 在 Spanner 中如何应用的吧。spanserver 存储数据的结构称为 tablet,大概相当于 RDBMS 中的表,虽然实际是将 tablet 存在 Colossus 中,但我们目前可以摒弃这些细节,就当作 tablet 是 spanserver 自己在维护就好。
每个 tablet 会在不同数据中心内进行备份,这是通过 Paxos 来完成的,相当每个 tablet 都是一个 Paxos 节点,由3~5个数据中心构成一个 Paxos Group,所以每次写入数据时,会在这些数据中心内完成备份。不过结合前面我们提到的 zone 是分隔 spanserver 的,我们可以认为 tablet 是在若干个 zone 之间进行了备份(从实际场景出发通常还是一个数据中心对应一个 zone,避免一损俱损)。
Paxos 协议需要在 Paxos Group 中选举出一个 Leader,所有的写请求都会转给 Leader 来完成;读请求可以由任意一个 up-to-date 的 Replica 完成回复。对于 Paxos 我了解的并不多,不过类比 Raft 应该还是能很好理解这些操作的。
值得注意的是,一个 spanserver 上可能有数百个 tablet,其中的每个 tablet 都对应着一个 Paxos 状态机,也就是一个 Paxos 节点;所以 Paxos Group 的构成单位是 tablet 而不是 spanserver。因此可能出现多个 spanserver 上都运行有 Paxos Leader Replica 的情况(个人猜测,仅供参考)。
最好理解的应该是一个 spanserver 对应一个 tablet,对应着一个 Paxos 节点;不过现在可能是一台服务器 A 运行了多个 tablet/Paxos节点,只不过 A 上 Paxos 节点对应的 peer 实际位于另一台服务器 B 上。

在 Figure 2 中我们还看到,每个 Leader 还对应 lock table 和 transaction manager 两个组件。lock table 实现了两阶段锁协议,来给 Leader Replica 执行写事务时授予锁的 // TODO: need update //。transaction manager 是用来协调分布式事务的,如果一个事务只涉及一个 Paxos Group,那么它相当于一个单机事务可以直接提交;但如果涉及多个 Group,那么就需要采用两阶段提交协议,其中一个 Group 将作为 coordinator,剩下的作为 participant 完成分布式事务的提交。
2.1 Directory and Data Model
这一节我们将看到 Spanner 中 Directory 的定义、独特的数据模型,以及 Spanner 这些独特的设计有何优势。
Spanner 中,一个 Directory 其实就是把一些具有公共前缀的 key 放在一块;我们在 BigTable 或者 LevelDB 中应该见过类似的思想了。一个 Paxos Group 可能包含多个 Directory,并且 placement driver 组件可能会将一些经常被共同访问的 Directory 放到同一个 Paxos Group 中,来降低读取/修改数据的延迟(将跨 Group 的分布式事务变为单个 Group 内的单节点事务就是一个巨大的提升了)。不过至于 placement driver 具体使用何种策略统计和移动数据我们就不得而知了。
Spanner 的数据模型也蛮有意思的,虽然我们第1节提到数据实际是以 key-value 的形式存储的,但是 Spanner 对外提供的依然是类似关系型数据库的关系模型:同样是一个二维表,每一行由若干列构成。 // TODO:more decription
// TODO: 关系模型
不同之处在于,Spanner 要求每个 table 需要定义可排序的 primary key,每个 table 其实就是 primary key 到 non-primary-key column 的映射(想想 Spanner 底层存储是 key-value 的形式就更好理解了)。另外,table 在 Spanner 中是按照有层级的,在下图中我们可以看到,可以在创建表时,通过 DIRECTORY 将一个表声明为 directory table;随后的 INTERLEAVE IN 会将 child table 的 row 会根据 key 的值存放到 directory table 对应的目录中。

这样设计的好处在于,客户端能够通过 DDL 语句来控制/预测数据在 Spanner 中的局部性,比如图中 Users 和 Albums 实体,我们能认为每个 User 对应的 Albums 数据都存放在同一个 Directory 中,在读取/修改数据时性能上就有很大的优势。另外 F1 也是利用了这一点来设计了 Hierachical Schema(细节留待下篇 F1 介绍)。
// TODO: 链接 //
3 True Time
True Time 的实现说起来也不复杂,只是成本比较高,公开了也难以复制。就跟高中班上学霸用奥赛的解法做压轴题拿了满分,给你抄你都得掂量一下;所以你最后选择用常规思路但是只能解第一小问,但是已经达到自己的要求了(我没暗示谁啊)。
True Time 是一个授时组件,提供 TT.now()/TT.after(t)/TT.before(t) 三个API,对应功能也容易看出分别是 当前时间/时间戳t是否为过去/时间戳t是否是未来的时间。不过 TT.now() 返回的并不是一个精确的时间戳,而是一个时间范围 TTinterval:[earliest, latest],Spanner 中称这段时间长度为 uncertainty,其实就是 True Time 授时可能出现的误差,但保证绝对时间(absolute time)是在该范围内的。
而 True Time 时间的获取,其实就是用 GPS 和原子钟互相校准来完成的。我们知道 GPS 的授时其实也是因为在卫星上搭载了原子钟;作为世界上最精确的时间测量工具,一般原子钟运行数千万年到数亿年,才会出现1秒的误差3。那么引申出来的问题是,为什么 Spanner 要同时使用这两种本质上一样的授时机制呢?
论文中给出的解释是:GPS 授时服务可能因为天线/接收器故障、无线电干扰、GPS系统问题等各种原因而不可用,而原子钟本身也可能出现时钟漂移以及其他不同类型的故障,因此谷歌认为有必要采纳两种授时手段来互相补足。所以壕无人性的在数据中心内混合部署了 GPS 和使用原子钟的 time master,甚至觉得原子钟和 GPS 的成本都差不多😡。time master 之间会定期同步时间,就我个人理解来看,time master 之间时间的误差其实并不会很大,授时的 uncertainty 主要还是保守的考虑了客户端本身的时钟漂移以及通信的延迟。我们将前面提到的时间窗口 TTinterval 的一半记为$\epsilon$,表示时间的不确定性,$\epsilon$ 的值通常在 1~7ms。
总结来说,True Time 其实就是在每个数据中心内设置了 GPS/原子钟 来授时,基本能够保证所有数据中心内时间的同步。现在我们终于可以用它来实现并发控制了。
// TODO:解决 uncertainty 的办法是等待该时间窗口过去? 也是问题,有什么意义?不等的话会出现什么问题?有没有例子? // TODO: 唯一?另外,授予的时间戳怎么用? // TODO: 那么,如果有两个包含冲突操作的事务 T1 < T2,在这种情况下数据的最终状态应是哪个?应该看到谁的修改?
4 并发控制
Spanner 一共支持4种事务类型。
| Operation | Concurrency Control | Replica Required |
|---|---|---|
| Read-Write Transaction | perssimistic | leader |
| Read-Only Transaction | lock-free | leader for timestamp; any for read |
| Snapshot Read, client-provided timestamp | lock-free | any |
| Snapshot Read, client-provided bound | lock-free | any |
比较容易产生疑问的是 Read-Only Txn 和 Snapshot Read 有什么区别:从表格中看它们都是 lock-free 的,而且都不产生 write。从我的理解来看,可以类比 MySQL 中的当前读和快照读:Read-Only Txn 总是读取当前最新的版本;而 Sanpshot Read 需要提供一个时间戳或者时间范围,Spanner 会去读取对应版本的数据(如果还没被垃圾回收的话)。因此,Spanner 中的写事务(即 Read-Write Transaction)也需要一个提交时间戳,用于判断 RW Txn 和 RO Txn 之间的先后次序。
Read-Write Txn
读写事务在 Spanner 中采用两阶段锁协议。回忆一下教材上的描述:使用两阶段锁的事务可以将它获取最后一个锁的时间点作为封锁点(lock point),并且可以按照 lock point 的顺序来得到事务的一个串行化顺序。因此,我们可以将 RW Txn 事务获取所有锁、到释放任意一个锁(即进入收缩阶段)之前的时间,作为 RW Txn 的提交时间。
Spanner 实际是将 Paxos Write 对应的时间戳作为事务的提交时间。 // TODO:more about Paxos Write
Spanner 保证每个 Paxos Group 的 Paxos Write 时间戳都是单调增的。在单个 Paxos Group 内这一点很容易理解,但是 Spanner 如何做到不同 Leader 之间时间戳也单调递增呢?这是来自论文 4.1.1 我们前面省略了的一个小节的内容: disjointness invariant: for each Paxos group, each Paxos leader’s lease interval is disjoint from every other leader’s. 这一性质的证明在论文的 Appendix A 中,我们现在暂且将其当作结论来使用。我在这里粗略的理解为,Spanner 会找到一个还没被使用过的最小时间戳来作为事务的提交时间戳。
// TODO: 其实如果有若干个单机事务同时提交,那么意味着它们之间数据没有交集,先后顺序应该无所谓;如果数据有交集,那么会变成分布式事务,提交时间戳由 Coordinator Leader 决定,这下时间戳应该就唯一了。
记写操作 $T_i$ 到达 corrdiantor leader 的提交请求为 $e_i^{server}$,spanner 会按照以下两条规则来执行事务和赋予时间戳: // TODO:needs update,==> Spanner 的事务需要满足以下两个条件,是为了。。。
-
Start
coordinator leader 为 $T_i$ 赋予一个提交时间戳 $s_i$(不晚于TT.now().latest) -
Commit Wait
coordinator leader 要确保客户端在 $TT.after(s_i)$ 条件为真之后,才能看到 $T_i$ 提交的数据。这一约束使得 $s_i$ 会早于 $T_i$ 提交的绝对时间(absolute commit time)。 // TODO:4.2.1
Spanner 中读写事务是将本次事务的修改缓存在客户端,事务提交时一并发给 Leader 提交;RW Txn 的读操作则需要向对应的 Leader 申请读锁(注意这是在读写事务中的 Read,是悲观的,所有操作都要锁),如果出现冲突则采用 wound-wait 来避免死锁(如果新事务请求的锁被老事务占有,则等待老事务释放;如果老事务请求的锁被新事务占用,则老事务回滚)。
思考:为何这里采用 wound-wait,有没有别的方法可以用来避免死锁?会有何不同?
// TODO:我的想法
RW Txn 提交时(假设是设计多个 Paxos Group 的两阶段提交),client 会选择一个 Paxos Group 作为 coordinator 向它的 leader 发送提交请求;同时也把请求和数据发送给其他的 participant leader,开始两阶段提交的 prepare 阶段。
接下来基本就是 2PC 的过程:
- 在 prepare 阶段,participant leader 生成一个 prepare 时间戳,将 prepare 的记录写入 Paxos,随后将时间戳发送给 coordinator leader;
- coordinator leader 收到所有 participant 的时间戳之后,生成事务的提交时间戳 s(必须大于所有 prepare 时间戳以及 leader 之前已经授予的时间戳),随后 coordinator 在 Paxos 中记录该事务已提交。在正常的 2PC 流程里,下一步应该是 participant 收到 leader 的提交消息,将该事务记为已提交并应用其修改;但 Spanner 在这步骤之前,需要进行一段时间的等待,得到
TT.after(s)返回 True。这是为了满足 Commit Wait 的约束。这个等待时间一般为 $2×\overline{\epsilon}$,不过由于 Paxos 之间通讯的开销,所以实际可能不需要等待这么久。随后才是 participant 记录事务提交、应用修改、释放锁,同时 client 也会收到事务提交的通知。
Spanner 中一个分布式读写事务的到这里就正式完成了。参考[4-1]来看,Spanner 这种提交方式,因为每个时间戳的平均不确定性 $\overline{\epsilon}=4ms$,每次提交需要等待 $2×\overline{\epsilon}=8ms$,因此 Spanner 对同一个数据项修改的读写事务理论上 TPS 只能达到 125;不过如果是两个数据项没有交集的读写事务,其实并不受此影响。据我猜测,Spanner 应用的场景里,通常是数据规模很大,比如存储数百万数千万个用户账户;但是并不会对每个用户的信息频繁进行修改,有可能整个 Spanner 每秒进行 10000 个事务,而每个事务都只涉及修改不同的 1~2 个用户。因为 Spanner 的高可扩展性,能够在很多个 Paxos Group 中完成这些事务,这样也能达到很高的吞吐量,而不是受限于我们上面分析的 125 TPS。
Read-Only Txn
Spanner 中的 RO Txn 依靠数据的时间戳来判断数据是否足够新,具体而言,每个 replica 维护一个安全时间戳(safe time),记为$t_{safe}$,表示当前 replica 已更新到的版本。如果 RO Txn 的时间戳小于$t_{safe}$,则可以直接读取 replica 的数据; 否则则会等待直到$t_{safe}$追赶上 RO Txn 的时间戳。
定义 $t_{safe} = min(t_{safe}^{Paxos}, t_{safe}^{TM})$;
$t_{safe}^{Paxos}$ 是最新的 Paxos Write 对应的时间戳;$t_{safe}^{TM}$ 是 Transaction Manager 的安全时间戳,如果没有事务处于就绪状态(即 2PC 两个阶段之间),则 $t_{safe}^{TM}=\infty$;如果存在这样的事务,则 $t_{safe}^{TM}=min_i(s_{i,g}^{prepare}) - 1$,因为事务 $T_i$ 的提交时间戳 $s_i$ 总是大于等于 $s_{i,g}^{prepare}$,因此可以将整个 Paxos Group 中最小的 prepare 时间戳作为安全时间戳。 // TODO:why?
实际 RO Txn 执行过程,其实首先需要先确定一个时间戳$s_{read}$,然后用$s_{read}$执行一次 Snapshot Read。最简单生成 $s_{read}$ 的策略就是令$s_{read}=TT.now().latest$,不过这种选取方法可能需要等待 $t_{safe}$ 追上 $s_{read}$,即会阻塞事务,Spanner 只在 RO Txn 涉及多个 Paxos Group 的情况下采用这种策略;如果 RO Txn 范围只涉及单个 Paxos Group,则实际上 Spanner 会将 Group 中最后一次提交 paxos write 的时间戳 LastTS() 作为$s_{read}$。
5 性能
在性能方面,论文中给出的数据显示,在使用3~5份 replica 时 Spanner 能达到 1~2w 的读取吞吐量,以及 2~3k 的写入吞吐量;写入平均延迟为 15ms 左右,读取延迟为 1.5ms 左右;在使用50个及以下 participant 的情况下,平均延迟增长并不明显,约为20~40ms;如果 participant 的规模增加到 100 以上,延迟才显著提升。
可用性方面,实验搭建了 5 个 zone,每个 zone 25 个 spanserver,所有 leader 位于 zone 1;由 100 个客户端总体以 50K reads/second 的速度发送读请求。实验设置了3种故障模式:
- non-leader kill:关闭 zone 2 中的 spanserver(non-leader)
结果:不影响吞吐量
原因:non-leader 负责响应读事务;被一个 non-leader zone 关闭后可以由其他 zone 继续响应。 - leader-soft kill:先通知 zone 1 中 server 切换 leader 然后再关闭
结果:吞吐量略微下降 3~4%
原因:读事务需要通过 leader 获取时间戳,关闭 leader 机器之前发送通知使集群能提前切换 leader,因此吞吐量并未下降太多。 - leader-hard kill:直接关闭 zone 1 的 leader
结果:直接降到0,重新选出 leader 后慢慢恢复 原因:重新选举 leader 过程中无法授予时间戳,无法响应读请求。
获取 True Time 的延迟,据论文中的数据来看,90%的 server 在 1ms 以下,99.9%的 server 都能在 10ms 内获得时间戳;并且在谷歌对网络升级、减少拥塞之后,该数字下降到约 5ms 左右。其他实验数据这里就不列举了,感兴趣的可以看原始论文。
总结
Spanner 应该可以算分布式关系型数据库的开创者了吧,支持SQL语法、支持分布式事务、保证线性一致性。在此之前的分布式数据库,多是通过 MySQL 作为底层存储,通过一系列中间件来实现分布式数据存储,还不能称为真正的分布式。不过 Spanner 通过 Paxos 共识来进行数据的备份,这不免会让人对其吞吐量上限产生好奇,尤其是 Spanner 使用 TrueTime 时间戳对应的 uncertainty 时间窗口平均达到 4ms、且需要根据时间戳来对事务进行全局排序这样的机制(也就是说理论上 TPS 应该没法达到太高)。2012年的论文对此没有过多讨论,只提及未来有可能将 uncertainty 降低至 1ms 以下,根据上面对TPS的分析,这确实也能够提升 TPS 上限。Future Work 中提及的其他可改进空间目前我还不理解其作用和意义,这里就暂时不讨论了;2017年谷歌发表了新的论文 Spanner: Becoming a SQL System,有机会我们了解一下经过几年的发展 Spanner 到底作出了什么样的改进吧。
The End