本意是想学习Linux的异步IO模型,而发现IO模型还有很多内容要补,故做此文。PS: gemini从《Unix网络编程》概括得到大纲,后续检索补全扩充内容。
引言
本以为Linux的IO模型只有同步和异步两种,检索之后发现比我想象的要多;可能以前上学的时候匆匆扫过,没在脑子里留下什么印象。现在来补补课吧,IO模型有下列5种:
一次完整的读操作(比如 read 或 recvfrom)会经历以下两个阶段:
- 阶段一:等待数据准备就绪 (Wait for data)
- 例如:等待网络上的数据包到达网卡,并被复制到内核的缓冲区中。
- 阶段二:将数据从内核空间拷贝到用户空间 (Copy data from kernel to user)
- 一旦内核缓冲区有数据了,系统需要把这些数据拷贝到应用程序的内存(用户空间)中,应用程序才能处理它们。
阻塞 I/O 模型 (Blocking IO)
最传统的IO模型,进程需要等待阶段一和阶段二执行完毕,才会被唤醒,接着往下执行其他操作。
read/write 就是采用这种工作方式。
sendfile绕过用户态直接发送数据,属于同步IO,但不清楚具体属于哪一类。
非阻塞 I/O 模型 (Non-blocking I/O)
进程在阶段一不断询问内核数据是否准备好(轮询 Polling),如果没有,则内核会返回一个EAGAIN错误避免阻塞;在阶段二阻塞等待拷贝数据。
1
2
3
4
5
6
#include <fcntl.h>
#include <unistd.h>
// 以只读且非阻塞的方式打开一个命名管道或设备文件
// 注意:这对普通磁盘文件往往没有实际的非阻塞效果
int fd = open("/dev/tty", O_RDONLY | O_NONBLOCK);
注释里说文件设置这个 flag 没有效果,是因为 Unix 将设备分为慢速和快速两类,socket 算慢速,磁盘算作快速的,设计VFS时认为返回 EAGAIN 并稍后再重发/查询结果的开销可能更高,因此没有给IO操作设计返回 EAGAIN 的机制。
如果是 Buffered IO,则read需要去 page cache 找,命中则直接返回;未命中,仍旧会让线程陷入睡眠,来等待数据从磁盘中加载上来(即使设置了非阻塞flag)。
如果是 Direct IO,那内核会直接让线程陷入睡眠等待IO操作结束。而 socket 则会在没有数据时立刻返回 EAGAIN,用法如下:
1
2
3
4
5
#include <sys/socket.h>
#include <netinet/in.h>
// 直接创建一个非阻塞的 TCP 套接字 (注意 SOCK_NONBLOCK)
int sockfd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, 0);
对这个 sockfd 调用读写操作,如果出现没数据或者缓冲区满,就会返回EAGAIN。
但要注意的是,此类IO模型虽然叫非阻塞,但并不能实现异步IO。目前搞不清楚这个命名是否是历史发展的遗留产物,有些容易造成误解。
I/O 多路复用模型 (I/O Multiplexing)
高并发网络编程常用IO模型,select、poll、epoll等都属于这一类。
- select: 使用一个1024 bitmap来维护所监听的fd状态是否更新。
- 缺点:遍历整个bitmap,效率不高
- poll: 改用数组/链表来维护fd,突破1024的限制。
- 缺点:依然需要遍历
- epoll: 使用以下3个API
- epoll_create:在内核中创建一个 epoll 对象,其底层是一个红黑树(用于高效存储和管理所有的 FD)和一个双向链表(用于存储就绪的 FD)。
- epoll_ctl:向红黑树中添加、修改或删除 FD。时间复杂度 $O(\log N)$。避免了每次等待时的全量拷贝。epoll_wait:阻塞等待事件。内核基于网卡中断驱动,当某个 FD 就绪时,内核会通过回调函数将其加入到就绪链表中。
- epoll_wait:只需要把这个就绪链表拷回用户态即可。
- 总结:epoll的优势在于没有fd数量限制,不需要O(N)遍历所有fd,查询就绪时通过回调函数直接将fd加入队列(不需要经过红黑树查找),可以直接O(1)返回。增删fd在操作红黑树,复杂度O(logN);红黑树也用于去重。因此能支持千万级别的并发。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
#include <iostream>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <fcntl.h>
#include <cstring>
constexpr int MAX_EVENTS = 1024;
constexpr int PORT = 8080;
// 将文件描述符设置为非阻塞模式 (ET 模式下必备)
void setNonBlocking(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
int main() {
// 1. 创建监听 Socket
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
sockaddr_in server_addr{};
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(PORT);
bind(listen_fd, (sockaddr*)&server_addr, sizeof(server_addr));
listen(listen_fd, SOMAXCONN);
setNonBlocking(listen_fd);
// 2. 创建 epoll 实例
int epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
std::cerr << "Failed to create epoll file descriptor\n";
return 1;
}
// 3. 将 listen_fd 注册到 epoll (使用边缘触发 EPOLLET)
epoll_event event;
event.data.fd = listen_fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &event);
epoll_event events[MAX_EVENTS];
std::cout << "Server listening on port " << PORT << "...\n";
// 4. 事件循环 (Event Loop)
while (true) {
// 阻塞等待事件发生,O(1) 唤醒
int num_events = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < num_events; ++i) {
int current_fd = events[i].data.fd;
if (current_fd == listen_fd) {
// 有新连接到来
sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int client_fd = accept(listen_fd, (sockaddr*)&client_addr, &client_len);
if (client_fd > 0) {
setNonBlocking(client_fd);
event.data.fd = client_fd;
event.events = EPOLLIN | EPOLLET; // 同样使用 ET 模式
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client_fd, &event);
std::cout << "New connection: " << client_fd << "\n";
}
} else if (events[i].events & EPOLLIN) {
// 现有连接有数据可读
char buffer[1024];
ssize_t bytes_read = read(current_fd, buffer, sizeof(buffer));
if (bytes_read > 0) {
// Echo back
write(current_fd, buffer, bytes_read);
} else if (bytes_read == 0 || (bytes_read == -1 && errno != EAGAIN)) {
// 客户端断开连接或发生错误
std::cout << "Client disconnected: " << current_fd << "\n";
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, current_fd, nullptr);
close(current_fd);
}
}
}
}
close(listen_fd);
close(epoll_fd);
return 0;
}
信号驱动 I/O 模型 (Signal-Driven I/O)
该模型下,进程不会阻塞在阶段一,而是直接返回,等到系统发送信号后再回来执行二阶段的数据拷贝。
// TODO:例子
异步 I/O 模型 (Asynchronous I/O - AIO)
本文学习的重头戏:Linux的异步IO模型,最早期POSIX(优缺点是什么),io_submit(限制是什么),最新的io_uring有什么优点。
POSIX AIO
Tips: POSIX(可移植操作系统接口,Portable Operating System Interface),是指Unix 及类 Unix 操作系统(如 Linux)一套 API、Shell 和工具接口。如果应用程序符合POSIX标准,则在不同系统间移植只需要少量甚至不需要代码修改;而 POSIX AIO 是最早为了支持异步IO引入的一套API。
早期的Linux没有支持异步IO,而是通过glibc库,在用户态创建了一个后台线程池去做IO,提供aio_read/aio_write借口,底层实现还是阻塞IO。
缺点是高并发时线程上下文切换开销大,性能差。至于为什么用户态线程模拟异步IO开销大,解释如下:
- 采用阻塞IO,线程会在做IO操作时让出CPU陷入睡眠,等待IO完成后硬件发出中断信号来唤醒。
- 内核在收到中断信号后在等待队列寻找对应线程,将其重新加入队列等待调度。
- 收到大量IO请求时,线程池中的线程就会被大量消耗,导致最终无线程可用;另外线程上下文切换本身也是开销非常高的操作。
思考:临时文件实现为每个线程带一个小buffer自己刷盘,会怎样?首先Linux内核里不会这样实现,这样不是一个统一的文件接口,每个线程要写文件还得自己先去申请一个小 buffer,比如说2MB。 导致大文件写入频繁陷入写入、刷盘、等待IO的切换当中,至少比一个大的 buffer pool 切换次数更多。 我在考虑这样是否给临时文件写入这一层加一堆前台线程,但是这样的模式跟 POSIX AIO 有什么区别?
io_submit
Linux 在 2.6 版本引入了真正的内核级异步 I/O,通过libaio库调用,提供io_submit/io_getevents接口。内核会在后台完成硬件交互后,再通知用户进程。
缺点是只能支持O_DIRECT,要求数据按照512B/4K对齐;如果是 Buffered IO 还会退回到阻塞模式,并且只支持磁盘文件,不支持网络IO;提交和获取结果需要用户态、内核态切换。
这也是目前数据库用得较多的异步IO模型,完美契合数据库的需求。
而 io_submit 实现异步IO的流程,实际上就是上学时OS课提到的几项概念组合:DMA+中断。
- 用户进程构造一个IO控制块,记录读取的文件描述符、内存地址、偏移量、大小。
- 调用io_submit,内核将IO请求提交给硬盘控制器,由DMA控制器往内存中拷贝数据;这期间CPU可以继续运行其它逻辑。
- 拷贝完成后,硬盘控制器向内核发送中断信号,内核响应后将IO标记为已完成。用户可以通过io_getevents来“收割”已经完成的IO。
io_uring
2019年 Linux 核心开发者 Jens Axboe(块设备维护者)重写的一套全新的异步 I/O 框架 io_uring。
原理:它在用户态和内核态之间创建了两个共享内存的环形缓冲区(Ring Buffers):
- SQ (Submission Queue):用户态程序把 I/O 任务放到这里。
- CQ (Completion Queue):内核把完成的结果放到这里。
优点:支持 Buffered I/O、Direct I/O、网络 Socket 读写(send/recv)、甚至是 accept 和 epoll。无需用户态和内核态之间的上下文切换,性能优于io_submit。
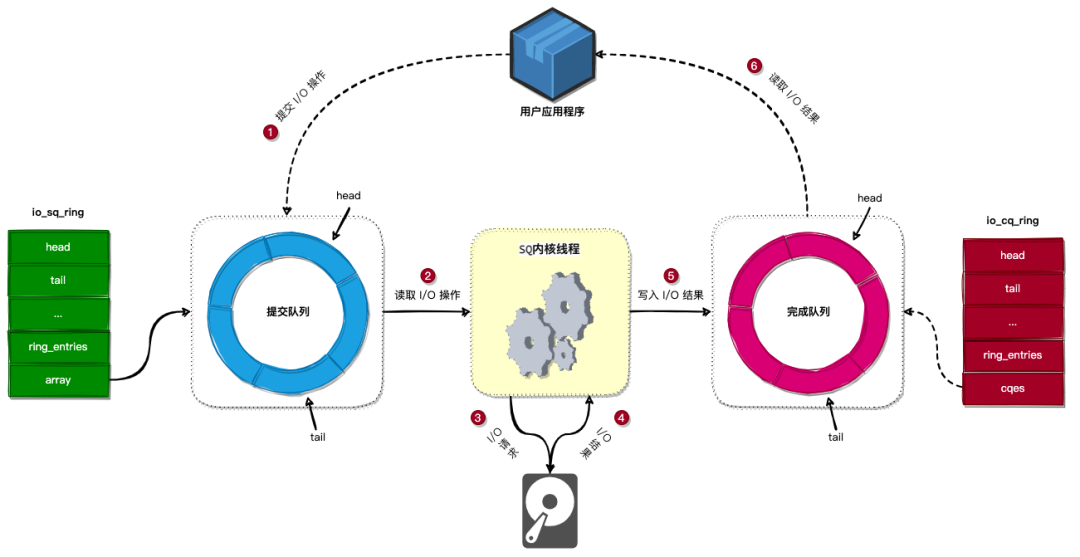
io_uring实例的无锁队列是单生产者单消费者,如果系统中存在多个生产者消费者,建议采用多个IO线程、每个线程自己创建一个io_uring实例,来保证线程安全。
io_uring有以下几种工作模式:
- 中断驱动模式 (Interrupt driven):默认的模式,类似epoll,用户通过io_uring_enter通知内核取数据之后,进程会被挂起,等待IO结束后触发中断唤醒。
- 轮询模式 (IOPOLL):调用io_uring_enter通知内核取数据之后不挂起,而是轮询IO是否完成。CPU开销高,但响应更快。
- 内核轮询模式 (SQPOLL):内核创建一个专属线程 io_sq_thread 来轮询拉取IO请求、处理已完成IO;用户进程无需调用 io_uring_enter 触发系统调用。该线程会独占一个CPU。
可以通过同时设置 IORING_SETUP_IOPOLL | IORING_SETUP_SQPOLL 来结合后两种模式,让用户线程代替专属IO线程,来完成轮询操作。
可以理解为什么OB没有采用,因为对OB来说是新东西;对数据库的大块IO而言提升不高,看内部测试只在单队列的场景下有明显提升,其他场景提升幅度不大。
旁路
类似于旁路导入于OB的作用,普通的网络读写、IO经过Linux若干层软件栈后,性能逐渐无法满足日益增长的数据传输需求。因此出现了一些通过“减少经过的软件栈”而提高系统性能的技术。
DPDK专注于网络数据包处理以提升网络I/O吞吐量,而SPDK专注于NVMe存储设备以显著降低存储延迟并提升IOPS。
SPDK
SPDK(Storage Performance Development Kit,存储性能开发套件)由 Intel 发起的一个开源软件集合。简单来说,传统的操作系统内核存储架构(如 Linux 内核栈)在面对现代极速 SSD 时,软件处理过程本身产生的开销(如系统调用、中断处理)已成为性能瓶颈。SPDK 的出现是为了“消除”这些瓶颈。
DPDK
DPDK (Data Plane Development Kit,数据面开发套件)也是 Intel 发起的,旨在通过旁路内核(Kernel Bypass)技术提升 I/O 性能。
DPDK轮询(Polling)和零拷贝技术将数据发送做在用户态,CPU直接在用户态处理数据,避免了内核协议栈的开销;而RDMA则是经过特定 NIC 网卡支持,直接将数据发送做到了硬件层面,完全不需要CPU参与。在高性能计算和大模型训练推理中,RDMA是主流。
二者对比
- 理论与商用上限:800Gbps
- 主流最高速率:目前最先进的网卡(如 NVIDIA ConnectX-8 SuperNIC)已原生支持单口 800Gbps 的带宽。
- 技术标准:
- RDMA (InfiniBand/RoCE):在 AI 智算中心中,最新的 XDR (Extended Data Rate) 标准支持单端口 800Gbps。
- DPDK (以太网):通过驱动高性能以太网卡,DPDK 同样可以跑满 800Gbps 的线速,但对 CPU 的核心数和 PCIe 6.0 总线有极高要求。
- 演进目标:1.6Tbps (1600Gbps)
- 研发阶段:下一代标准(如 InfiniBand 的 GDR 或最新的 Broadcom 1.6T 交换芯片)正在推动单口 1.6Tbps 的实现。
- 瓶颈挑战:要实现 1.6Tbps,服务器必须配备 PCIe Gen6 x16 插槽(单向带宽约 1Tbps,双向 2Tbps),否则接口会先于网络达到饱和。
即,二者都可以跑满800Gbps带宽,但DPDK对CPU的消耗更高,需要8~16核才能处理800Gb报文。
DPU
前阵子有了解到 SDN 中会使用特殊硬件DPU,同样能达到减轻CPU负担、提升网络传输效率的效果。也顺带看一下跟RDMA的区别。
DPU 以SoC(System On Chip)形式存在,专门负责处理网络、存储、安全等基础层数据密集型任务,将CPU从这些“脏活累活”中解放出来,专注于应用计算。目前了解到的可以由DPU卸载的操作有:
- 网络协议处理:比如IP解析、校验等
- 数据加密/解密:HTTPS的数据传输后需要加密解密
理论上有RDMA网卡的,CPU传输数据的负担就减轻到头了。但是DPU还能做的事情有:减轻虚拟化与多租户开销。使用RDMA需要维护映射表,这也是消耗算力的。这部分开销可以下沉到DPU来做。数据中心可以卖给客户更多的核心,DPU价格比顶级CPU便宜,跟主流CPU相当,但能耗更低。在大规模数据中心里应用能节省电力消耗,应用场景就从这些地方抠出来的。
总结
从IO模型扩展开真的有很多内容需要学习,如果未来有机会应用,而不是学过后就有应用场景的知识,那还是有一些兴趣学下去的。加油!
The End